
Data Reality Check
Why AI Adoption Breaks Down Before Scale and What Leaders Are Missing


Executive summary
AI did not stall in 2025 because organizations lacked ambition, tools, or access to models. It stalled because trust broke down, and trust breaks first at the data layer.
AI did not stall because organizations lacked ambition. It stalled because trust broke down, and trust breaks first at the data layer.
Across mid market and regulated organizations, I am seeing the same pattern repeat. Teams experiment with AI successfully, then hesitate when it is time to rely on it. Outputs feel inconsistent. Decisions feel risky. Accountability feels unclear.
This is not a model problem.
This is not a training problem.
This is not a resistance problem.
It is a data reality problem.
AI maturity is capped by data maturity, and data maturity is now a leadership and operating issue.
In 2026, organizations that confront this reality directly will begin scaling AI with confidence. Those that do not will continue experimenting, mistaking activity for progress.
The moment leaders are running into right now
For many leaders, the AI conversation shifted quietly in late 2025.
The excitement did not disappear.
Pilots did not stop.
Tools did not suddenly fail.
What changed was confidence.
“We tried it, but we do not trust it enough to rely on it.”
“We tried it, but we do not trust it enough to rely on it.”
That hesitation is not philosophical.
It is operational.
Leaders are accountable for decisions, risk, and outcomes. When AI outputs feel inconsistent, incomplete, or difficult to explain, usage naturally stalls.
Trusting the system feels irresponsible.
The question executives are asking but not saying out loud
“Our data has always been messy. Why is this suddenly a blocker now?”
It is a fair question.
The difference is not that data suddenly became worse.
AI changed the consequences.
For decades, imperfect data fed reports after decisions were made. Humans absorbed inconsistency. Judgment compensated.
AI moves data upstream into decisions themselves.
AI does not tolerate ambiguity the way organizations do.
That is why data reality feels unavoidable now.
The most persistent myth leaders still believe
“We have a lot of data.”
This statement is usually true.
It is also usually irrelevant.
Having data is not the same as having usable data.
AI systems surface this gap fast.
When data is fragmented, inconsistently defined, or poorly governed, AI does not fail loudly. It fails quietly.
Wrong enough to erode confidence.
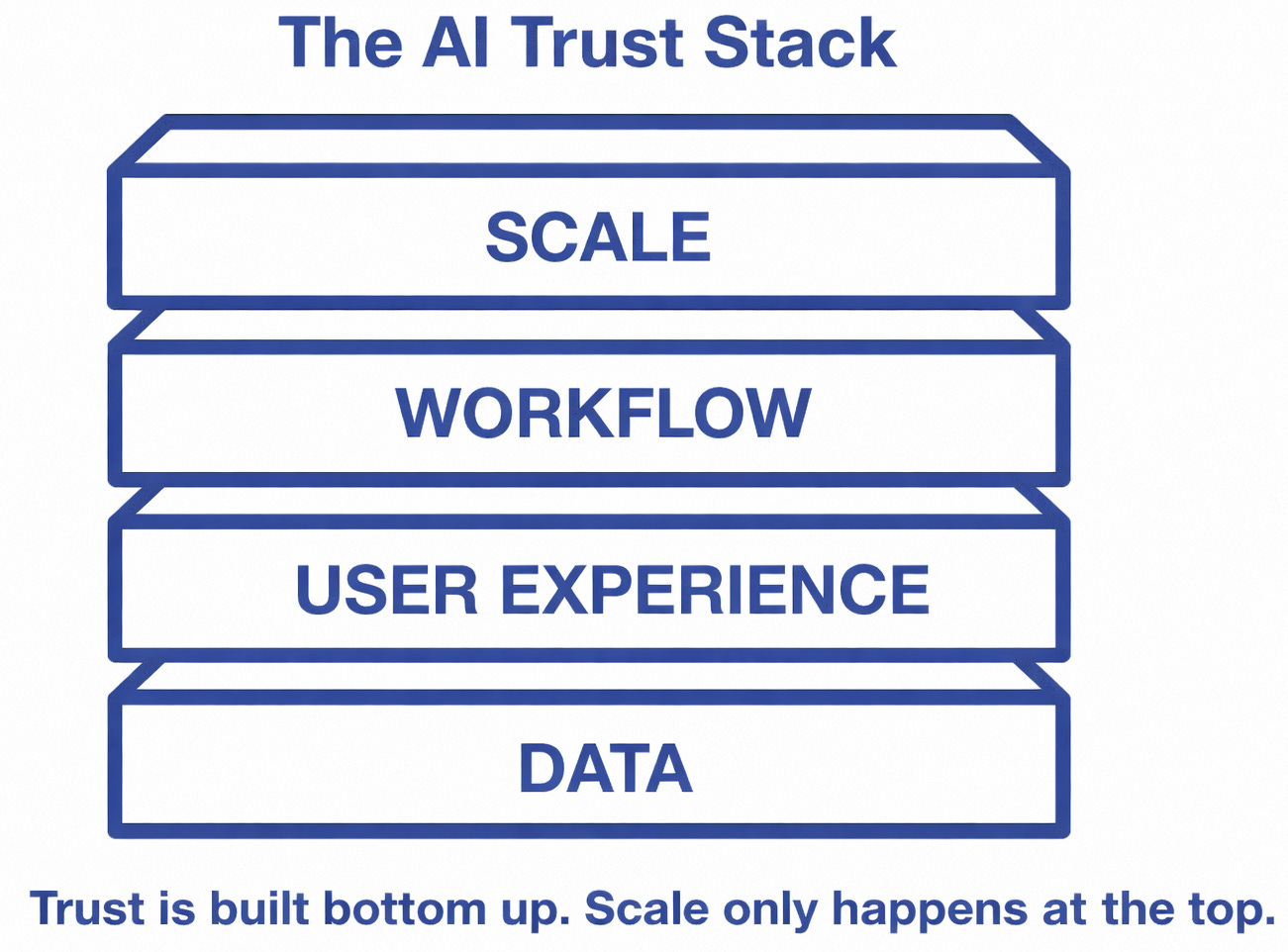
Why trust breaks before adoption takes hold
Most leaders assume adoption fails because of resistance or training gaps.
In reality, users ask three questions:
Do I understand where this output came from?
Can I explain it to someone else?
Am I accountable if it is wrong?
When those answers are unclear, usage drops.
People do not resist AI because they dislike it. They resist because they do not want to be the one left holding the consequences.
Data ownership is the layer most organizations skip
When AI initiatives stall, the reflex is predictable.
Better tools.
Cleaner pipelines.
More advanced models.
Those help performance.
They rarely fix adoption.
The real question is simpler: who owns the data when it informs a decision?
Data ownership is not about control. It is about knowing who stands behind the output when it matters.
Grounding this in mid market reality
Most mid market organizations do not have the luxury of perfect data programs.
That is reality, not failure.
Data readiness is not about fixing everything. It is about choosing deliberately.
The question is not:
“Is all our data ready?”
The question is:
Which decisions matter enough to warrant clarity, ownership, and standards?
The cost of avoiding this conversation
Organizations that avoid data reality make the same tradeoff.
They constrain AI to low risk assistance while competitors embed it into decisions.
Over time, this shows up as:
Slower cycle times
Higher manual review costs
Increased operational drag
Quiet erosion of advantage
The gap does not appear dramatic at first. It compounds slowly, then all at once.
Why good data still fails without the right experience
Even when data improves, adoption often still lags.
Outputs are better.
Governance is clearer.
Users still hesitate.

Why user experience is the next constraint leaders will hit
Once data reality is confronted, the next breakdown follows.
Data improves.
Ownership clarifies.
Governance matures.
Trust still does not follow automatically.
User experience is decision confidence infrastructure.
That is the next constraint most leaders will hit.
That is the next piece in this series.
Final thought
AI advantage in 2026 will not come from access to better models.
Everyone will have access.
Most organizations will continue experimenting. A smaller group will build systems they are willing to rely on.
That distinction will matter far more than any model release.
💡 Enjoyed this article?
📩 Subscribe to The Strategy Signal for weekly insights at the intersection of data, AI, and transformation, and the human stories behind them.
🔗 Follow me on LinkedIn for more reflections on data, leadership, and life.
🌐 Learn more about how Sapient Advisors helps leaders turn information into action, and vision into impact.
From signal → strategy → growth.
When decisions are automated, uncertainty stops being an inconvenience and becomes a risk.
Maribeth, I agree that AI adoption often stalls at the data layer, your technical diagnosis is sharp and necessary. I always enjoy seeing this through your lens.
My addition: when users ask “Am I accountable if it’s wrong?”, they’re navigating not just messy data but risk that flows downward onto them. They also don’t yet know whether their hard‑won skill at interpreting ambiguous data is being quietly devalued or is about to become even more critical. That human capacity to absorb the change, while carrying diffuse accountability and potential expertise disruption, may be as binding a constraint as data maturity itself.